Learning to Learn Words from Visual Scenes
2 University of Illinois at Urbana-Champaign

When we travel, we often encounter new scenarios we have never experienced before, with new sights and new words that describe them. We can use our language-learning ability to quickly learn these new words and correlate them with the visual world. In contrast, language models often do not robustly generalize to novel words and compositions.
We propose a framework that learns how to learn text representations from visual context. Experiments show that our approach significantly outperforms the state-of-the-art in visual language modeling for acquiring new words and predicting new compositions. Model ablations and visualizations suggest that the visual modality helps our approach more robustly generalize at these tasks.
Paper

Acquiring New Words
We propose a meta-learning approach that learns to learn a visual language model for generalization. We construct training episodes containing a reference set of text-image scenes and a target example. To train the model, we mask input elements from the target, and ask the model to reconstruct them by pointing to them in the reference set. Our model can describe scenes with words not seen during training by pointing to them.




skin
of
garlic
the
peel
off
of
the
onion
pieces
of
pepper
from
sink
carrot
peelings




open
the
cupboard4%wash
plates
with
rag
close
oven95%switch
off
on
the
right




pan
tablecloth
bag
into
the
bin
plate




get
avocado62%still
taking
skin33%off
fish3%stir
rice
into
pan
peel
Video Presentation
Presentation as an Oral to the CVPR 2020 Minds vs. Machines workshopCode and model
Our model uses Transformers to operate on both visual input and text. For code and pretrained models, go to our Github project.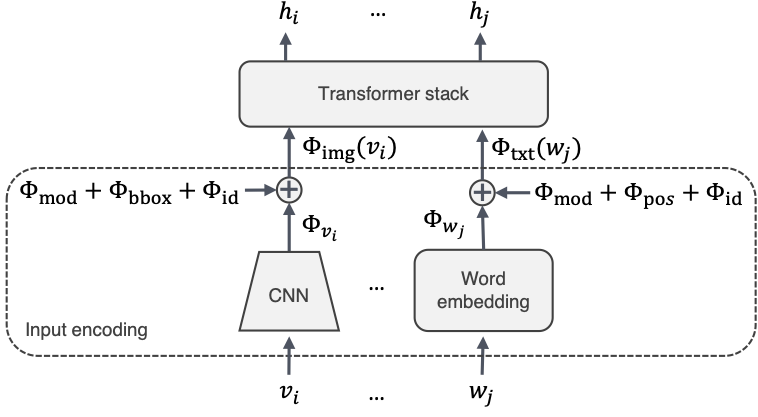
Acknowledgements
Funding for this research was provided by DARPA GAILA HR00111990058. We thank Nvidia for GPU donations. The webpage template was inspired by this project page.